FF整理を放置し続けた結果、フォロワー数に対してフォロー数が異常に多いアカウント(大抵ただの相互フォロー目的だったり就活関係の監視垢だったりする)がフォロワーに増えてきたので、一括整理を行いました。
FFの一覧を取得する
いろいろなやり方がありますが、今回は「Pochitter!」というWindows用のフリーソフトを使いました。APIキーなどの取得は不要で、起動時にTwitterのユーザー名とパスワードを入力するだけで、自分のFFを取得することができます。メニュー>オプション>CSV形式で保存 を行うことで、表示されている内容をCSVファイルで取得できました。
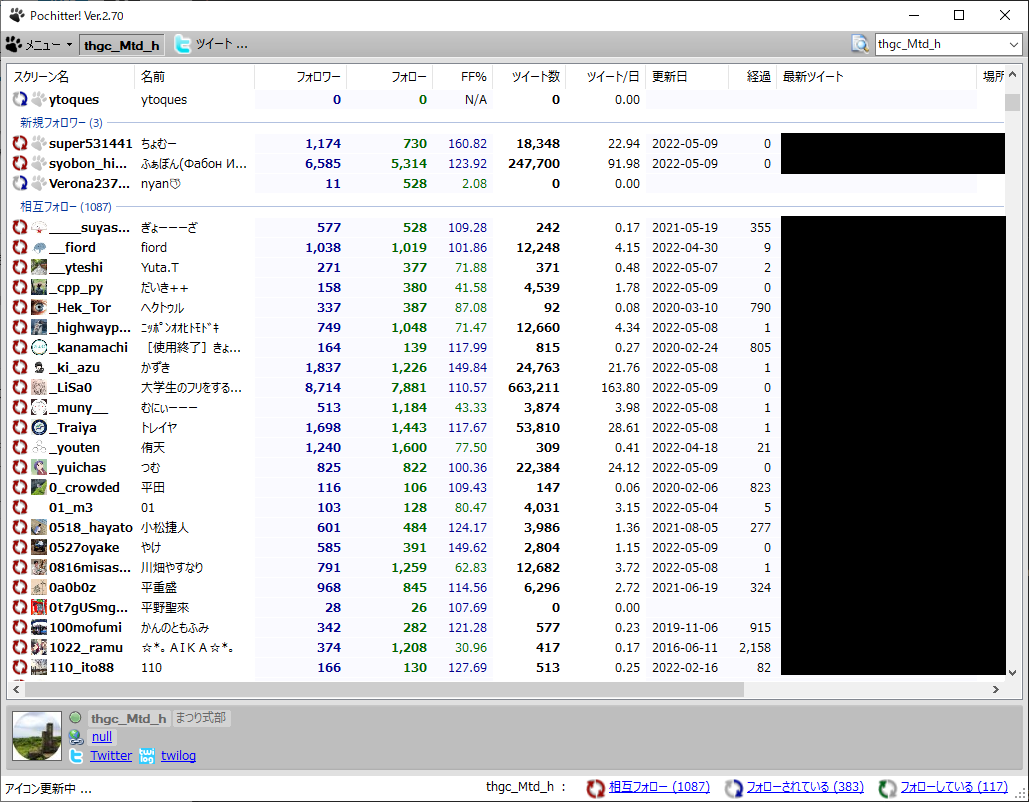
ブロ解したいアカウントを抽出する
今回は、取得したCSVの中から「FF%(フォロワー / フォロー)」が 0.5 以下のアカウントを抽出しCSVとして保存します。その中で、友人などブロ解したくないアカウントだけを取り除き、削除したいアカウント一覧を作ります。データ整理でおなじみの Python の pandas ライブラリを使いましょう。
import pandas as pd
df = pd.read_csv('FFlist.csv') # Pochitterで出力したcsvからpd.DataFrameをつくる
はいエラー。
Traceback (most recent call last):
File "C:\Users\xxxx\...\main.py", line 2, in <module>
df = pd.read_csv('FFlist.csv', encoding='utf8')
(中略)
File "C:\Users\xxxx\AppData\Local\Programs\Python\Python310\lib\site-packages\pandas\io\parsers\c_parser_wrapper.py", line 225, in read
chunks = self._reader.read_low_memory(nrows)
File "pandas\_libs\parsers.pyx", line 805, in pandas._libs.parsers.TextReader.read_low_memory
File "pandas\_libs\parsers.pyx", line 861, in pandas._libs.parsers.TextReader._read_rows
File "pandas\_libs\parsers.pyx", line 847, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas\_libs\parsers.pyx", line 1960, in pandas._libs.parsers.raise_parser_error
pandas.errors.ParserError: Error tokenizing data. C error: Expected 12 fields in line 84, saw 13
CSVファイルの84行目を読み取れないとのこと。確認しましょう。
EachFollow,xxxxxxxx,"XXXX",True,True,127,168,1775,2015-03-20,"The word ,\"impossible \",is not in my dictionary.",https://twitter.com/xxxxxxxx,null
ユーザー名等ぼかしていますが、自己紹介文の中に入っていたダブルクオーテーションがエスケープされなかったことが原因で読めなかったようです。バックスラッシュをエスケープシーケンスに指定して再実行。
import pandas as pd
df = pd.read_csv('FFlist.csv', escapechar='\\') # Pochitterで出力したcsvからpd.DataFrameをつくる
df が 取得できました。それでは、FF% が 0.5 以下の行をdf_removeに抽出し、FF_remove.csv というファイル名で保存します。
df_remove = df[df.FollowersCount / df.FollowingCount < 0.5] # FF% 0.5 未満の行を抽出
df_remove.to_csv('FF_remove.csv', index=False) # CSVに保存
抽出されたファイルを覗くと、「相互フォロー」とか「量子力学の基礎」とか怪しい名前が並んでいますが、中にはリア友がいたりするので、ブロ解したくないアカウントの行はExcel使って手動で消しました。
リストアップしたアカウントをブロ解
ブラウザの自動操作ができる Selenium を使って、上で作った削除したいアカウント一覧を片っ端からブロック→ブロック解除していきます。コードは以下の通り。
import pandas as pd
import time
from selenium import webdriver
# 自分のユーザー名
username = input("username = ")
# 自分のパスワード
password = input("password = ")
driver = webdriver.Chrome('C:\\Users\\xxxx\\chromedriver_win32\\chromedriver.exe') # chromedriver.exeへのパス
driver.get("https://twitter.com/login") # ログインページへ移動
time.sleep(3)
# ユーザ名をインプットする
username_box = driver.find_element_by_xpath('//*[@id="layers"]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div/div/div/div[5]/label/div/div[2]/div/input')
username_box.send_keys(username)
time.sleep(1)
# 次へをクリックする
next_button = driver.find_element_by_xpath('//*[@id="layers"]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div/div/div/div[6]')
next_button.click()
time.sleep(2)
# パスワードをインプットする
password_box = driver.find_element_by_xpath('//*[@id="layers"]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div[1]/div/div/div[3]/div/label/div/div[2]/div[1]/input')
password_box.send_keys(password)
time.sleep(1)
# ログインボタンをクリック
login_button = driver.find_element_by_xpath('//*[@id="layers"]/div/div/div/div/div/div/div[2]/div[2]/div/div/div[2]/div[2]/div[2]/div/div[1]/div/div')
login_button.click()
time.sleep(3)
# 削除したいフォロワーを記したCSVを読み込む
df_remove = pd.read_csv('FF_remove.csv')
# 各フォロワーに対して処理を実施
for screenname in df_remove['ScreenName']:
try:
# 当該ユーザーのプロフィールページへ移動
driver.get("https://twitter.com/" + screenname)
time.sleep(3)
# ユーザーアクションメニューをクリック
menu = driver.find_element_by_css_selector('div[data-testid="userActions"]')
menu.click()
time.sleep(0.5)
# ブロックするをクリック
block_menu = driver.find_element_by_css_selector('div[data-testid="block"]')
block_menu.click()
time.sleep(0.5)
# 確認ポップアップでブロックをクリック
block_popup = driver.find_element_by_xpath('//*[@id="layers"]/div[2]/div/div/div/div/div/div[2]/div[2]/div[2]/div[1]')
block_popup.click()
time.sleep(2)
# ブロック中の赤いボタンをクリック
unblock_button = driver.find_element_by_xpath('//*[@id="react-root"]/div/div/div[2]/main/div/div/div/div/div/div[2]/div/div/div[1]/div/div[1]/div[2]/div[2]/div/div')
unblock_button.click()
time.sleep(0.5)
# 確認ポップアップのブロック解除をクリック
unblock_popup = driver.find_element_by_xpath('//*[@id="layers"]/div[2]/div/div/div/div/div/div[2]/div[2]/div[2]/div[1]')
unblock_popup.click()
except:
# エラーがあったときのみログを出す
print(f"ScreenName {screenname} Remove Failed!")
参考にしたサイト
先駆者として大いに参考にしたのはこの2つ。
- 便利!! Twitterのフォロー管理が簡単になるフリーソフト 『Pochitter!』 一覧表示で見やすい | PCあれこれ探索
- 【初心者のpython入門】seleniumでフォロー自動化!〜Twitter編〜 | Analytics Board | python特化のプログラミングサイト
Pandas も Selenium も使い慣れているわけではないので、こまごまとした参考書。
- https://hack-le.com/pandas-csv-xlsx/
- https://pythondatascience.plavox.info/pandas/%E8%A1%8C%E3%83%BB%E5%88%97%E3%81%AE%E6%8A%BD%E5%87%BA
- https://note.nkmk.me/python-pandas-to-csv/
- https://note.nkmk.me/python-pandas-drop/
- https://note.nkmk.me/python-pandas-dataframe-for-iteration/
- https://ai-inter1.com/python-selenium/
- https://chromedriver.chromium.org/downloads
- https://posipochi.com/2021/05/03/python-scraping-css-selector/#toc7